Tensorflow Basics
TensorFlow로 논리 문제 (AND 연산) 풀어보기
경사하강법 (Gradient Descent)
- 현재 모형의 오차를 구한다.
- 오차를 가장 많이 줄일 수 있는 방향을 찾는다.
- 그 방향으로 일정 폭만큼 계수를 수정한다.
- 더 이상 오차가 줄어들지 않을 때까지 반복한다.
Tensorflow 설치 (Windows)
pip3 install –upgrade tensorflow
pip3 install –upgrade tensorlayer
Tensorflow Basics
import tensorflow as tf
import tensorlayer as tl
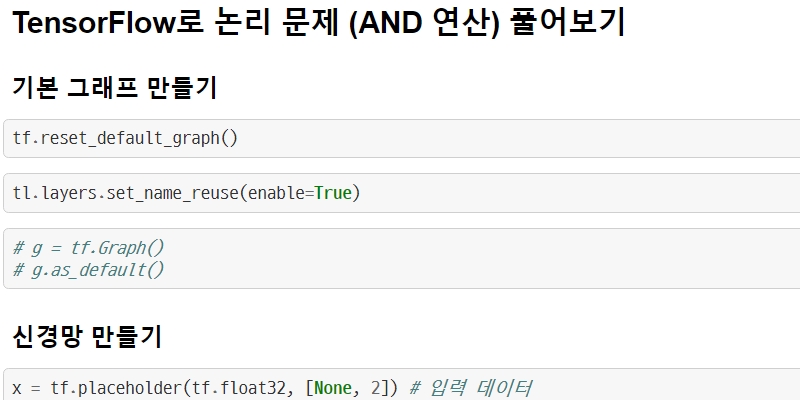
TensorFlow로 논리 문제 (AND 연산) 풀어보기
기본 그래프 만들기
tf.reset_default_graph()
tl.layers.set_name_reuse(enable=True)
# g = tf.Graph()
# g.as_default()
신경망 만들기
x = tf.placeholder(tf.float32, [None, 2]) # 입력 데이터
x
<tf.Tensor 'Placeholder:0' shape=(?, 2) dtype=float32>
network = tl.layers.InputLayer(x) # 입력층
[TL] InputLayer input_layer: (?, 2)
network = tl.layers.DenseLayer(network, n_units=2, act=tf.sigmoid, name="hidden") # 은닉층
[TL] DenseLayer hidden: 2 sigmoid
network = tl.layers.DenseLayer(network, n_units=1, act=tf.sigmoid, name="output") # 출력층
[TL] DenseLayer output: 1 sigmoid
Cost
predict = network.outputs # 예측값 넣을 변수
y = tf.placeholder(tf.float32, [None, 1]) # 실제 값
cost = tl.cost.binary_cross_entropy(predict, y) # cost function
데이터 설정
import numpy
xdata = numpy.array([[0, 0], [1, 0], [0, 1], [1, 1]])
ydata = numpy.array([0, 0, 0, 1]).reshape((4, 1)) # AND 연산
data = {x: xdata, y: ydata}
data
{<tf.Tensor 'Placeholder:0' shape=(?, 2) dtype=float32>: array([[0, 0],
[1, 0],
[0, 1],
[1, 1]]),
<tf.Tensor 'Placeholder_1:0' shape=(?, 1) dtype=float32>: array([[0],
[0],
[0],
[1]])}
Gradient Descent Optimizer
- learning_rate가 너무 작으면 학습 속도가 느리고, 너무 높으면 학습이 불안정하다. 적당히 잘 설정할 것이 중요.
gd = tf.train.GradientDescentOptimizer(learning_rate=1)
train_step = gd.minimize(cost) # cost를 최소화한다
세션과 변수 초기화
session = tf.InteractiveSession()
session.run(tf.global_variables_initializer())
그래프에서 세션을 실행하여 예측을 수행
predict.eval(data) # 초기 예측값
array([[ 0.48621923],
[ 0.48598829],
[ 0.48589399],
[ 0.48566353]], dtype=float32)
cost.eval(data) # 초기 비용
0.67975819
학습을 한 단계 더 진행
session.run(train_step, data)
predict.eval(data) # 예측값이 변화됨.
array([[ 0.39910471],
[ 0.39846507],
[ 0.39813268],
[ 0.39749503]], dtype=float32)
cost.eval(data) # 비용이 감소한 것을 확인
0.61197412
반복해서 학습
tl.utils.fit(session, network, train_step, cost, xdata, ydata, x, y,
batch_size=4, # 한 번에 4개의 데이터 학습
n_epoch=1000, # 최대 1000회까지
print_freq=100 # 100번 학습마다 비용을 출력
)
Start training the network ...
Epoch 1 of 1000 took 0.018012s, loss 0.611974
Epoch 100 of 1000 took 0.001017s, loss 0.313797
Epoch 200 of 1000 took 0.001000s, loss 0.083118
Epoch 300 of 1000 took 0.000000s, loss 0.035179
Epoch 400 of 1000 took 0.000000s, loss 0.020720
Epoch 500 of 1000 took 0.000500s, loss 0.014304
Epoch 600 of 1000 took 0.001004s, loss 0.010787
Epoch 700 of 1000 took 0.000502s, loss 0.008599
Epoch 800 of 1000 took 0.000000s, loss 0.007118
Epoch 900 of 1000 took 0.000502s, loss 0.006055
Epoch 1000 of 1000 took 0.000000s, loss 0.005257
Total training time: 0.588794s
predict.eval(data) # 최종 예측. 네번째 값은 1에 가깝고, 나머지는 0에 가깝다.
array([[ 1.33482739e-04],
[ 3.88649176e-03],
[ 3.89132788e-03],
[ 9.87009406e-01]], dtype=float32)
numpy.set_printoptions(suppress=True) # 수치가 e-9 형식으로 표시될 경우 일반적인 형태로 표시하게 설정
predict.eval(data) # 최종 예측 다시 출력
array([[ 0.00013348],
[ 0.00388649],
[ 0.00389133],
[ 0.98700941]], dtype=float32)
session.close()