Merging DataFrames
여러 파일에서 데이터 읽기, 데이터 합치기, Merge with inner/left/outer join
import pandas as pd
import numpy as np
1. Reading multiple data files
filenames = ['sales_gold.csv', 'sales_silver.csv', 'sales_bronze.csv']
# 1. Loop
dataframes = []
for filename in filenames:
dataframes.append(pd.read_csv('data/'+filename))
dataframes[0].head()
| item | total | |
|---|---|---|
| 0 | apple | 500 |
| 1 | orange | 300 |
| 2 | peach | 200 |
| 3 | berry | 100 |
# 2. comprehension
dataframes = [pd.read_csv('data/'+f) for f in filenames]
dataframes[0].head()
| item | total | |
|---|---|---|
| 0 | apple | 500 |
| 1 | orange | 300 |
| 2 | peach | 200 |
| 3 | berry | 100 |
# 3. glob
from glob import glob
filenames = glob('data/sales*.csv')
dataframes = [pd.read_csv(f) for f in filenames]
dataframes[0].head()
| month | total | |
|---|---|---|
| 0 | apple | 600 |
| 1 | orange | 750 |
| 2 | peach | 570 |
| 3 | berry | 210 |
# combine
filenames
['data/sales_bronze.csv', 'data/sales_gold.csv', 'data/sales_silver.csv']
items = dataframes[1].copy()
items.columns = ['item','gold']
items['silver'] = dataframes[2]['total']
items['bronze'] = dataframes[0]['total']
items
| item | gold | silver | bronze | |
|---|---|---|---|---|
| 0 | apple | 500 | 700 | 600 |
| 1 | orange | 300 | 550 | 750 |
| 2 | peach | 200 | 400 | 570 |
| 3 | berry | 100 | 180 | 210 |
index & sort
items2 = items.set_index('item')
items2
| gold | silver | bronze | |
|---|---|---|---|
| item | |||
| apple | 500 | 700 | 600 |
| orange | 300 | 550 | 750 |
| peach | 200 | 400 | 570 |
| berry | 100 | 180 | 210 |
items2.sort_index()
| gold | silver | bronze | |
|---|---|---|---|
| item | |||
| apple | 500 | 700 | 600 |
| berry | 100 | 180 | 210 |
| orange | 300 | 550 | 750 |
| peach | 200 | 400 | 570 |
items2.sort_values('gold')
| gold | silver | bronze | |
|---|---|---|---|
| item | |||
| berry | 100 | 180 | 210 |
| peach | 200 | 400 | 570 |
| orange | 300 | 550 | 750 |
| apple | 500 | 700 | 600 |
# Reindexing DataFrame from a list
itemlist = ['apple', 'banana', 'berry', 'orange', 'peach', 'mango']
items3 = items2.reindex(itemlist)
items3
| gold | silver | bronze | |
|---|---|---|---|
| item | |||
| apple | 500.0 | 700.0 | 600.0 |
| banana | NaN | NaN | NaN |
| berry | 100.0 | 180.0 | 210.0 |
| orange | 300.0 | 550.0 | 750.0 |
| peach | 200.0 | 400.0 | 570.0 |
| mango | NaN | NaN | NaN |
# Reindexing using another DataFrame Index
items4 = items3.reindex(items2.index)
items4
| gold | silver | bronze | |
|---|---|---|---|
| item | |||
| apple | 500.0 | 700.0 | 600.0 |
| orange | 300.0 | 550.0 | 750.0 |
| peach | 200.0 | 400.0 | 570.0 |
| berry | 100.0 | 180.0 | 210.0 |
Arithmetic with Series & DataFrames
df = pd.DataFrame({'Date':['2017-01-10','2017-01-11','2017-01-12'], 'TemperatureF':[32,25,34]})
temps_f = df.set_index('Date')
temps_f
| TemperatureF | |
|---|---|
| Date | |
| 2017-01-10 | 32 |
| 2017-01-11 | 25 |
| 2017-01-12 | 34 |
temps_f.info()
<class 'pandas.core.frame.DataFrame'>
Index: 3 entries, 2017-01-10 to 2017-01-12
Data columns (total 1 columns):
TemperatureF 3 non-null int64
dtypes: int64(1)
memory usage: 48.0+ bytes
temps_c = ((temps_f - 32) * 5/9).round(2)
temps_c.columns = temps_c.columns.str.replace('F', 'C')
temps_c
| TemperatureC | |
|---|---|
| Date | |
| 2017-01-10 | 0.00 |
| 2017-01-11 | -3.89 |
| 2017-01-12 | 1.11 |
2. Concatenating data
- result = s1.append(s2).append(s3)
- result = pd.concat([s1, s2, s3])
df1 = pd.DataFrame({'area':['CT', 'MA', 'NY'], 'stores':[320,205,845]})
df_area1 = df1.set_index('area')
df_area1
| stores | |
|---|---|
| area | |
| CT | 320 |
| MA | 205 |
| NY | 845 |
df2 = pd.DataFrame({'area':['FL', 'GA', 'AL'], 'stores':[90,115,25]})
df_area2 = df2.set_index('area')
df_area2
| stores | |
|---|---|
| area | |
| FL | 90 |
| GA | 115 |
| AL | 25 |
# append
store = df_area1.append(df_area2)
store
| stores | |
|---|---|
| area | |
| CT | 320 |
| MA | 205 |
| NY | 845 |
| FL | 90 |
| GA | 115 |
| AL | 25 |
# concat
store = pd.concat([df_area1, df_area2])
store
| stores | |
|---|---|
| area | |
| CT | 320 |
| MA | 205 |
| NY | 845 |
| FL | 90 |
| GA | 115 |
| AL | 25 |
# Dataframe의 컬럼이 서로 다른 경우
df_area1
| stores | |
|---|---|
| area | |
| CT | 320 |
| MA | 205 |
| NY | 845 |
df3 = pd.DataFrame({'area':['FL', 'NY', 'AL'], 'members':[90,115,25]})
df_area3 = df3.set_index('area')
df_area3
| members | |
|---|---|
| area | |
| FL | 90 |
| NY | 115 |
| AL | 25 |
store = df_area1.append(df_area3) # ---> index 동일한 것이 있으면 중복.
store
| members | stores | |
|---|---|---|
| area | ||
| CT | NaN | 320.0 |
| MA | NaN | 205.0 |
| NY | NaN | 845.0 |
| FL | 90.0 | NaN |
| NY | 115.0 | NaN |
| AL | 25.0 | NaN |
store = pd.concat([df_area1, df_area3], axis=1) # index 동일한 것은 하나로 묶음.
store
| stores | members | |
|---|---|---|
| AL | NaN | 25.0 |
| CT | 320.0 | NaN |
| FL | NaN | 90.0 |
| MA | 205.0 | NaN |
| NY | 845.0 | 115.0 |
Concat using multi-index on rows / columns
df2015 = df_area1.copy()
df2015
| stores | |
|---|---|
| area | |
| CT | 320 |
| MA | 205 |
| NY | 845 |
df1 = pd.DataFrame({'area':['CT', 'MA', 'NY'], 'stores':[839,560,745]})
df2016 = df1.set_index('area')
df2016
| stores | |
|---|---|
| area | |
| CT | 839 |
| MA | 560 |
| NY | 745 |
df_store = pd.concat([df2015, df2016], keys=[2015,2016], axis=0)
df_store
| stores | ||
|---|---|---|
| area | ||
| 2015 | CT | 320 |
| MA | 205 | |
| NY | 845 | |
| 2016 | CT | 839 |
| MA | 560 | |
| NY | 745 |
df_store = pd.concat([df2015, df2016], keys=[2015,2016], axis='columns')
df_store
| 2015 | 2016 | |
|---|---|---|
| stores | stores | |
| area | ||
| CT | 320 | 839 |
| MA | 205 | 560 |
| NY | 845 | 745 |
concat with Dictionary
store_dic = {2015:df2015, 2016:df2016}
df_store = pd.concat(store_dic, axis='columns')
df_store
| 2015 | 2016 | |
|---|---|---|
| stores | stores | |
| area | ||
| CT | 320 | 839 |
| MA | 205 | 560 |
| NY | 845 | 745 |
inner join / outer join
df_area1
| stores | |
|---|---|
| area | |
| CT | 320 |
| MA | 205 |
| NY | 845 |
df_area3
| members | |
|---|---|
| area | |
| FL | 90 |
| NY | 115 |
| AL | 25 |
pd.concat([df_area1, df_area3], axis=1, join='inner')
| stores | members | |
|---|---|---|
| area | ||
| NY | 845 | 115 |
pd.concat([df_area1, df_area3], axis=1, join='outer')
| stores | members | |
|---|---|---|
| AL | NaN | 25.0 |
| CT | 320.0 | NaN |
| FL | NaN | 90.0 |
| MA | 205.0 | NaN |
| NY | 845.0 | 115.0 |
3. Merging DataFrames
# pd.merge : index가 없는 DataFrame 들을 컬럼 기준으로 합친다.
컬럼명이 서로 다른 경우
df1 = pd.DataFrame({'area':['CT', 'MA', 'NY'], 'stores':[320,205,845]})
df1
| area | stores | |
|---|---|---|
| 0 | CT | 320 |
| 1 | MA | 205 |
| 2 | NY | 845 |
df2 = pd.DataFrame({'area':['FL', 'NY', 'AL'], 'members':[90,115,25]})
df2
| area | members | |
|---|---|---|
| 0 | FL | 90 |
| 1 | NY | 115 |
| 2 | AL | 25 |
pd.merge(df1, df2)
| area | stores | members | |
|---|---|---|---|
| 0 | NY | 845 | 115 |
컬럼명이 서로 같은 경우
df2015 = pd.DataFrame({'area':['CT', 'MA', 'NY'], 'stores':[320,205,845]})
df2016 = pd.DataFrame({'area':['CT', 'MA', 'NY'], 'stores':[900,115,250]})
pd.merge(df2015, df2016)
| area | stores |
|---|
pd.merge(df2015, df2016, on='area')
| area | stores_x | stores_y | |
|---|---|---|---|
| 0 | CT | 320 | 900 |
| 1 | MA | 205 | 115 |
| 2 | NY | 845 | 250 |
pd.merge(df2015, df2016, on='area', suffixes=['_2015', '_2016'])
| area | stores_2015 | stores_2016 | |
|---|---|---|---|
| 0 | CT | 320 | 900 |
| 1 | MA | 205 | 115 |
| 2 | NY | 845 | 250 |
기준이 되는 컬럼명이 서로 다른 경우
df1 = pd.DataFrame({'area':['CT', 'MA', 'NY'], 'stores':[320,205,845]})
df2 = pd.DataFrame({'state':['CT', 'MA', 'NY'], 'stores':[900,115,250]})
pd.merge(df1, df2, left_on='area', right_on='state')
| area | stores_x | state | stores_y | |
|---|---|---|---|---|
| 0 | CT | 320 | CT | 900 |
| 1 | MA | 205 | MA | 115 |
| 2 | NY | 845 | NY | 250 |
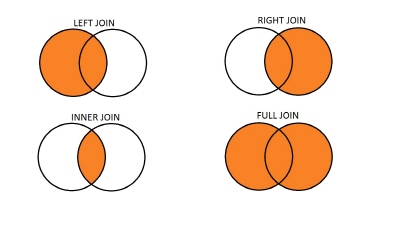
Merging with inner / left / outer join
df2015 = pd.DataFrame({'area':['NY', 'MA', 'CT'], 'stores':[320,205,845]})
df2016 = pd.DataFrame({'area':['CT', 'TX', 'NY'], 'stores':[900,115,250]})
pd.merge(df2015, df2016, on='area', suffixes=['_2015', '_2016']) # inner
| area | stores_2015 | stores_2016 | |
|---|---|---|---|
| 0 | NY | 320 | 250 |
| 1 | CT | 845 | 900 |
pd.merge(df2015, df2016, on='area', suffixes=['_2015', '_2016'], how='left')
| area | stores_2015 | stores_2016 | |
|---|---|---|---|
| 0 | NY | 320 | 250.0 |
| 1 | MA | 205 | NaN |
| 2 | CT | 845 | 900.0 |
pd.merge(df2015, df2016, on='area', suffixes=['_2015', '_2016'], how='right')
| area | stores_2015 | stores_2016 | |
|---|---|---|---|
| 0 | NY | 320.0 | 250 |
| 1 | CT | 845.0 | 900 |
| 2 | TX | NaN | 115 |
pd.merge(df2015, df2016, on='area', suffixes=['_2015', '_2016'], how='outer')
| area | stores_2015 | stores_2016 | |
|---|---|---|---|
| 0 | NY | 320.0 | 250.0 |
| 1 | MA | 205.0 | NaN |
| 2 | CT | 845.0 | 900.0 |
| 3 | TX | NaN | 115.0 |
# Ordered Merge
pd.merge_ordered(df2015, df2016, on='area', suffixes=['_2015', '_2016'], how='outer')
| area | stores_2015 | stores_2016 | |
|---|---|---|---|
| 0 | CT | 845.0 | 900.0 |
| 1 | MA | 205.0 | NaN |
| 2 | NY | 320.0 | 250.0 |
| 3 | TX | NaN | 115.0 |