Manipulating DataFrames
Data indexing, slicing, filtering & transforming. Change index, reshaping & pivot. Detect outliers.
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
# setting plot defatult size
%pylab inline
pylab.rcParams['figure.figsize'] = (12, 6)
Populating the interactive namespace from numpy and matplotlib
1. Extracting and transforming data
df = pd.read_csv('data/election2012.csv')
df = df.loc[df.state == 'PA']
df.head()
| state | county | Obama | Romney | winner | total | margin | turnout | |
|---|---|---|---|---|---|---|---|---|
| 2957 | PA | Adams | 35.5 | 63.1 | Romney | 41383 | 27.6 | 1.4 |
| 2958 | PA | Allegheny | 56.6 | 42.2 | Obama | 607455 | 14.4 | 1.2 |
| 2959 | PA | Armstrong | 30.7 | 67.9 | Romney | 27925 | 37.2 | 1.4 |
| 2960 | PA | Beaver | 46.0 | 52.6 | Romney | 78951 | 6.6 | 1.4 |
| 2961 | PA | Bedford | 22.1 | 77.0 | Romney | 21239 | 54.9 | 0.9 |
indexing & slicing
election = df.set_index('county')
election.head()
| state | Obama | Romney | winner | total | margin | turnout | |
|---|---|---|---|---|---|---|---|
| county | |||||||
| Adams | PA | 35.5 | 63.1 | Romney | 41383 | 27.6 | 1.4 |
| Allegheny | PA | 56.6 | 42.2 | Obama | 607455 | 14.4 | 1.2 |
| Armstrong | PA | 30.7 | 67.9 | Romney | 27925 | 37.2 | 1.4 |
| Beaver | PA | 46.0 | 52.6 | Romney | 78951 | 6.6 | 1.4 |
| Bedford | PA | 22.1 | 77.0 | Romney | 21239 | 54.9 | 0.9 |
p_counties = election.loc['Perry':'Potter']
p_counties
| state | Obama | Romney | winner | total | margin | turnout | |
|---|---|---|---|---|---|---|---|
| county | |||||||
| Perry | PA | 29.8 | 68.6 | Romney | 17941 | 38.8 | 1.6 |
| Philadelphia | PA | 85.2 | 14.1 | Obama | 648864 | 71.1 | 0.7 |
| Pike | PA | 43.9 | 54.9 | Romney | 22883 | 11.0 | 1.2 |
| Potter | PA | 26.3 | 72.2 | Romney | 7091 | 45.9 | 1.5 |
p_counties = election.loc['Potter':'Perry':-1] # reverse
p_counties
| state | Obama | Romney | winner | total | margin | turnout | |
|---|---|---|---|---|---|---|---|
| county | |||||||
| Potter | PA | 26.3 | 72.2 | Romney | 7091 | 45.9 | 1.5 |
| Pike | PA | 43.9 | 54.9 | Romney | 22883 | 11.0 | 1.2 |
| Philadelphia | PA | 85.2 | 14.1 | Obama | 648864 | 71.1 | 0.7 |
| Perry | PA | 29.8 | 68.6 | Romney | 17941 | 38.8 | 1.6 |
filtering
turnout_df = election[election['turnout'] < 1]
turnout_df
| state | Obama | Romney | winner | total | margin | turnout | |
|---|---|---|---|---|---|---|---|
| county | |||||||
| Bedford | PA | 22.1 | 77.0 | Romney | 21239 | 54.9 | 0.9 |
| Philadelphia | PA | 85.2 | 14.1 | Obama | 648864 | 71.1 | 0.7 |
low_margin = election[(election.margin < 3) & (election.turnout < 3)] # or = |
low_margin
| state | Obama | Romney | winner | total | margin | turnout | |
|---|---|---|---|---|---|---|---|
| county | |||||||
| Berks | PA | 48.9 | 49.5 | Romney | 160752 | 0.6 | 1.6 |
| Bucks | PA | 50.0 | 48.8 | Obama | 315474 | 1.2 | 1.2 |
| Centre | PA | 48.9 | 49.0 | Romney | 67374 | 0.1 | 2.1 |
| Chester | PA | 49.2 | 49.7 | Romney | 245512 | 0.5 | 1.1 |
| Mercer | PA | 48.0 | 50.6 | Romney | 47386 | 2.6 | 1.4 |
# 득표율 차이가 3% 이내이면 winner 를 NULL 처리.
too_close_row = election['margin'] < 3
election.loc[too_close_row, 'winner'] = np.nan
election.info()
<class 'pandas.core.frame.DataFrame'>
Index: 67 entries, Adams to York
Data columns (total 7 columns):
state 67 non-null object
Obama 67 non-null float64
Romney 67 non-null float64
winner 62 non-null object
total 67 non-null int64
margin 67 non-null float64
turnout 67 non-null float64
dtypes: float64(4), int64(1), object(2)
memory usage: 4.2+ KB
election['winner'].value_counts()
Romney 51
Obama 11
Name: winner, dtype: int64
Trasforming DataFrames : apply()
# test data
sales = pd.DataFrame({'month':['Jan','Feb','Mar','Apr','May','Jun'],
'eggs':[47,110,226,82,132,210],
'salt':[12,50,89,87,np.nan,60],
'spam':[17,31,72,20,52,55]})
sales = sales.set_index('month')
sales
| eggs | salt | spam | |
|---|---|---|---|
| month | |||
| Jan | 47 | 12.0 | 17 |
| Feb | 110 | 50.0 | 31 |
| Mar | 226 | 89.0 | 72 |
| Apr | 82 | 87.0 | 20 |
| May | 132 | NaN | 52 |
| Jun | 210 | 60.0 | 55 |
# convert to dozon unit function
def dozens(n):
return n//12
sales.apply(dozens)
| eggs | salt | spam | |
|---|---|---|---|
| month | |||
| Jan | 3 | 1.0 | 1 |
| Feb | 9 | 4.0 | 2 |
| Mar | 18 | 7.0 | 6 |
| Apr | 6 | 7.0 | 1 |
| May | 11 | NaN | 4 |
| Jun | 17 | 5.0 | 4 |
sales.apply(lambda n: n//12)
| eggs | salt | spam | |
|---|---|---|---|
| month | |||
| Jan | 3 | 1.0 | 1 |
| Feb | 9 | 4.0 | 2 |
| Mar | 18 | 7.0 | 6 |
| Apr | 6 | 7.0 | 1 |
| May | 11 | NaN | 4 |
| Jun | 17 | 5.0 | 4 |
sales['dozen_spam'] = sales.spam.apply(dozens)
sales['salty_spam'] = sales.salt + sales.spam
sales
| eggs | salt | spam | dozen_spam | salty_spam | |
|---|---|---|---|---|---|
| month | |||||
| Jan | 47 | 12.0 | 17 | 1 | 29.0 |
| Feb | 110 | 50.0 | 31 | 2 | 81.0 |
| Mar | 226 | 89.0 | 72 | 6 | 161.0 |
| Apr | 82 | 87.0 | 20 | 1 | 107.0 |
| May | 132 | NaN | 52 | 4 | NaN |
| Jun | 210 | 60.0 | 55 | 4 | 115.0 |
map() with a dictionary
red_vs_blue = {'Obama':'blue', 'Romney':'red'}
election['color'] = election.winner.map(red_vs_blue)
election.head()
| state | Obama | Romney | winner | total | margin | turnout | color | |
|---|---|---|---|---|---|---|---|---|
| county | ||||||||
| Adams | PA | 35.5 | 63.1 | Romney | 41383 | 27.6 | 1.4 | red |
| Allegheny | PA | 56.6 | 42.2 | Obama | 607455 | 14.4 | 1.2 | blue |
| Armstrong | PA | 30.7 | 67.9 | Romney | 27925 | 37.2 | 1.4 | red |
| Beaver | PA | 46.0 | 52.6 | Romney | 78951 | 6.6 | 1.4 | red |
| Bedford | PA | 22.1 | 77.0 | Romney | 21239 | 54.9 | 0.9 | red |
from scipy.stats import zscore
turnout_zscore = zscore(election['turnout']) # z-score
election['turnout_zscore'] = turnout_zscore
election.tail()
| state | Obama | Romney | winner | total | margin | turnout | color | turnout_zscore | |
|---|---|---|---|---|---|---|---|---|---|
| county | |||||||||
| Washington | PA | 42.7 | 56.0 | Romney | 88958 | 13.3 | 1.3 | red | -0.507754 |
| Wayne | PA | 38.8 | 59.8 | Romney | 20669 | 21.0 | 1.4 | red | -0.133913 |
| Westmoreland | PA | 37.6 | 61.3 | Romney | 166809 | 23.7 | 1.1 | red | -1.255436 |
| Wyoming | PA | 42.9 | 55.2 | Romney | 11001 | 12.3 | 1.9 | red | 1.735292 |
| York | PA | 38.7 | 59.9 | Romney | 183702 | 21.2 | 1.4 | red | -0.133913 |
Change Index
sales.index = [idx.upper() for idx in sales.index]
sales.head(3)
| eggs | salt | spam | dozen_spam | salty_spam | |
|---|---|---|---|---|---|
| JAN | 47 | 12.0 | 17 | 1 | 29.0 |
| FEB | 110 | 50.0 | 31 | 2 | 81.0 |
| MAR | 226 | 89.0 | 72 | 6 | 161.0 |
sales.index.name = 'MONTHS'
sales.head(3)
| eggs | salt | spam | dozen_spam | salty_spam | |
|---|---|---|---|---|---|
| MONTHS | |||||
| JAN | 47 | 12.0 | 17 | 1 | 29.0 |
| FEB | 110 | 50.0 | 31 | 2 | 81.0 |
| MAR | 226 | 89.0 | 72 | 6 | 161.0 |
Hierarchical indexing / multi index
# make test data
sales = pd.DataFrame({'state':['CA','CA','TX','TX','NY','NY'], 'month':[1,2,1,2,1,2],
'eggs':[47,110,221,77,69,88],
'salt':[12,50,89,87,73,49], 'spam':[17,31,72,20,37,56]})
sales
| eggs | month | salt | spam | state | |
|---|---|---|---|---|---|
| 0 | 47 | 1 | 12 | 17 | CA |
| 1 | 110 | 2 | 50 | 31 | CA |
| 2 | 221 | 1 | 89 | 72 | TX |
| 3 | 77 | 2 | 87 | 20 | TX |
| 4 | 69 | 1 | 73 | 37 | NY |
| 5 | 88 | 2 | 49 | 56 | NY |
sales2 = sales.set_index(['state','month']) # multi index
sales2
| eggs | salt | spam | ||
|---|---|---|---|---|
| state | month | |||
| CA | 1 | 47 | 12 | 17 |
| 2 | 110 | 50 | 31 | |
| TX | 1 | 221 | 89 | 72 |
| 2 | 77 | 87 | 20 | |
| NY | 1 | 69 | 73 | 37 |
| 2 | 88 | 49 | 56 |
sales2.index # 인덱스 정보 조회
MultiIndex(levels=[['CA', 'NY', 'TX'], [1, 2]],
labels=[[0, 0, 2, 2, 1, 1], [0, 1, 0, 1, 0, 1]],
names=['state', 'month'])
sales2.loc[('NY', 1)]
eggs 69
salt 73
spam 37
Name: (NY, 1), dtype: int64
sales2.loc['CA']
| eggs | salt | spam | |
|---|---|---|---|
| month | |||
| 1 | 47 | 12 | 17 |
| 2 | 110 | 50 | 31 |
2. Rearranging and reshaping data
Pivot / Stack & Unstack
sales = pd.DataFrame({'weekday':['Sun','Sun','Mon','Mon'],
'item':['egg','spam','egg','spam'],
'sold':[120,250,189,187],
'retail':[17,31,72,20]})
sales
| item | retail | sold | weekday | |
|---|---|---|---|---|
| 0 | egg | 17 | 120 | Sun |
| 1 | spam | 31 | 250 | Sun |
| 2 | egg | 72 | 189 | Mon |
| 3 | spam | 20 | 187 | Mon |
pivot_sold = sales.pivot(index='weekday', columns='item', values='sold')
pivot_sold
| item | egg | spam |
|---|---|---|
| weekday | ||
| Mon | 189 | 187 |
| Sun | 120 | 250 |
pivot_sales = sales.pivot(index='weekday', columns='item')
pivot_sales
| retail | sold | |||
|---|---|---|---|---|
| item | egg | spam | egg | spam |
| weekday | ||||
| Mon | 72 | 20 | 189 | 187 |
| Sun | 17 | 31 | 120 | 250 |
stack & unstack : 참조블로그
sales = sales.set_index(['weekday','item'])
sales
| retail | sold | ||
|---|---|---|---|
| weekday | item | ||
| Sun | egg | 17 | 120 |
| spam | 31 | 250 | |
| Mon | egg | 72 | 189 |
| spam | 20 | 187 |
byweekday = sales.unstack(level='weekday')
byweekday
| retail | sold | |||
|---|---|---|---|---|
| weekday | Mon | Sun | Mon | Sun |
| item | ||||
| egg | 72 | 17 | 189 | 120 |
| spam | 20 | 31 | 187 | 250 |
byweekday.stack(level='weekday')
| retail | sold | ||
|---|---|---|---|
| item | weekday | ||
| egg | Mon | 72 | 189 |
| Sun | 17 | 120 | |
| spam | Mon | 20 | 187 |
| Sun | 31 | 250 |
byitem = sales.unstack(level='item')
byitem
| retail | sold | |||
|---|---|---|---|---|
| item | egg | spam | egg | spam |
| weekday | ||||
| Mon | 72 | 20 | 189 | 187 |
| Sun | 17 | 31 | 120 | 250 |
byitem.stack(level='item')
| retail | sold | ||
|---|---|---|---|
| weekday | item | ||
| Mon | egg | 72 | 189 |
| spam | 20 | 187 | |
| Sun | egg | 17 | 120 |
| spam | 31 | 250 |
Melting DataFrames : 참조블로그
sales = pd.DataFrame({'weekday':['Sun','Sun','Mon','Mon'],
'item':['egg','spam','egg','spam'],
'sold':[120,250,189,187],
'retail':[17,31,72,20]})
sales
| item | retail | sold | weekday | |
|---|---|---|---|---|
| 0 | egg | 17 | 120 | Sun |
| 1 | spam | 31 | 250 | Sun |
| 2 | egg | 72 | 189 | Mon |
| 3 | spam | 20 | 187 | Mon |
sales2 = pd.melt(sales, id_vars=['weekday'], value_name='value')
sales2
| weekday | variable | value | |
|---|---|---|---|
| 0 | Sun | item | egg |
| 1 | Sun | item | spam |
| 2 | Mon | item | egg |
| 3 | Mon | item | spam |
| 4 | Sun | retail | 17 |
| 5 | Sun | retail | 31 |
| 6 | Mon | retail | 72 |
| 7 | Mon | retail | 20 |
| 8 | Sun | sold | 120 |
| 9 | Sun | sold | 250 |
| 10 | Mon | sold | 189 |
| 11 | Mon | sold | 187 |
sales3 = pd.melt(sales, id_vars=['weekday','item'])
sales3
| weekday | item | variable | value | |
|---|---|---|---|---|
| 0 | Sun | egg | retail | 17 |
| 1 | Sun | spam | retail | 31 |
| 2 | Mon | egg | retail | 72 |
| 3 | Mon | spam | retail | 20 |
| 4 | Sun | egg | sold | 120 |
| 5 | Sun | spam | sold | 250 |
| 6 | Mon | egg | sold | 189 |
| 7 | Mon | spam | sold | 187 |
kv_pairs = pd.melt(sales, col_level=0)
kv_pairs.tail()
| variable | value | |
|---|---|---|
| 11 | sold | 187 |
| 12 | weekday | Sun |
| 13 | weekday | Sun |
| 14 | weekday | Mon |
| 15 | weekday | Mon |
pivot_table & aggregation
sales
| item | retail | sold | weekday | |
|---|---|---|---|---|
| 0 | egg | 17 | 120 | Sun |
| 1 | spam | 31 | 250 | Sun |
| 2 | egg | 72 | 189 | Mon |
| 3 | spam | 20 | 187 | Mon |
by_item_day = sales.pivot_table(index='weekday', columns='item')
by_item_day
| retail | sold | |||
|---|---|---|---|---|
| item | egg | spam | egg | spam |
| weekday | ||||
| Mon | 72 | 20 | 189 | 187 |
| Sun | 17 | 31 | 120 | 250 |
sales.pivot_table(index='weekday', aggfunc=sum)
| retail | sold | |
|---|---|---|
| weekday | ||
| Mon | 92 | 376 |
| Sun | 48 | 370 |
sales.pivot_table(index='weekday', aggfunc=sum, margins=True) # All 포함.
| retail | sold | |
|---|---|---|
| weekday | ||
| Mon | 92.0 | 376.0 |
| Sun | 48.0 | 370.0 |
| All | 140.0 | 746.0 |
3. Grouping data
titanic = pd.read_csv('data/titanic.csv')
titanic.head()
| id | survived | pclass | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
by_class = titanic.groupby('pclass')
by_class
<pandas.core.groupby.DataFrameGroupBy object at 0x10eefaf28>
by_class['survived'].count()
pclass
1 216
2 184
3 491
Name: survived, dtype: int64
by_class_sub = by_class[['age','fare']]
aggregated = by_class_sub.agg(['max','median','mean'])
aggregated
| age | fare | |||||
|---|---|---|---|---|---|---|
| max | median | mean | max | median | mean | |
| pclass | ||||||
| 1 | 80.0 | 37.0 | 38.233441 | 512.3292 | 60.2875 | 84.154687 |
| 2 | 70.0 | 29.0 | 29.877630 | 73.5000 | 14.2500 | 20.662183 |
| 3 | 74.0 | 24.0 | 25.140620 | 69.5500 | 8.0500 | 13.675550 |
aggregated.loc[:, ('age','max')]
pclass
1 80.0
2 70.0
3 74.0
Name: (age, max), dtype: float64
titanic.groupby(['embarked','pclass'])['survived'].count()
embarked pclass
C 1 85
2 17
3 66
Q 1 2
2 3
3 72
S 1 127
2 164
3 353
Name: survived, dtype: int64
Aggregating on index levels/fields
titanic_idx = pd.read_csv('data/titanic.csv', index_col=['pclass','sex']).sort_index()
titanic_idx
| id | survived | name | age | sibsp | parch | ticket | fare | cabin | embarked | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| pclass | sex | ||||||||||
| 1 | female | 2 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| female | 4 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | |
| female | 12 | 1 | Bonnell, Miss. Elizabeth | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S | |
| female | 32 | 1 | Spencer, Mrs. William Augustus (Marie Eugenie) | NaN | 1 | 0 | PC 17569 | 146.5208 | B78 | C | |
| female | 53 | 1 | Harper, Mrs. Henry Sleeper (Myna Haxtun) | 49.0 | 1 | 0 | PC 17572 | 76.7292 | D33 | C | |
| female | 62 | 1 | Icard, Miss. Amelie | 38.0 | 0 | 0 | 113572 | 80.0000 | B28 | NaN | |
| female | 89 | 1 | Fortune, Miss. Mabel Helen | 23.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S | |
| female | 137 | 1 | Newsom, Miss. Helen Monypeny | 19.0 | 0 | 2 | 11752 | 26.2833 | D47 | S | |
| female | 152 | 1 | Pears, Mrs. Thomas (Edith Wearne) | 22.0 | 1 | 0 | 113776 | 66.6000 | C2 | S | |
| female | 167 | 1 | Chibnall, Mrs. (Edith Martha Bowerman) | NaN | 0 | 1 | 113505 | 55.0000 | E33 | S | |
| female | 178 | 0 | Isham, Miss. Ann Elizabeth | 50.0 | 0 | 0 | PC 17595 | 28.7125 | C49 | C | |
| female | 195 | 1 | Brown, Mrs. James Joseph (Margaret Tobin) | 44.0 | 0 | 0 | PC 17610 | 27.7208 | B4 | C | |
| female | 196 | 1 | Lurette, Miss. Elise | 58.0 | 0 | 0 | PC 17569 | 146.5208 | B80 | C | |
| female | 216 | 1 | Newell, Miss. Madeleine | 31.0 | 1 | 0 | 35273 | 113.2750 | D36 | C | |
| female | 219 | 1 | Bazzani, Miss. Albina | 32.0 | 0 | 0 | 11813 | 76.2917 | D15 | C | |
| female | 231 | 1 | Harris, Mrs. Henry Birkhardt (Irene Wallach) | 35.0 | 1 | 0 | 36973 | 83.4750 | C83 | S | |
| female | 257 | 1 | Thorne, Mrs. Gertrude Maybelle | NaN | 0 | 0 | PC 17585 | 79.2000 | NaN | C | |
| female | 258 | 1 | Cherry, Miss. Gladys | 30.0 | 0 | 0 | 110152 | 86.5000 | B77 | S | |
| female | 259 | 1 | Ward, Miss. Anna | 35.0 | 0 | 0 | PC 17755 | 512.3292 | NaN | C | |
| female | 269 | 1 | Graham, Mrs. William Thompson (Edith Junkins) | 58.0 | 0 | 1 | PC 17582 | 153.4625 | C125 | S | |
| female | 270 | 1 | Bissette, Miss. Amelia | 35.0 | 0 | 0 | PC 17760 | 135.6333 | C99 | S | |
| female | 276 | 1 | Andrews, Miss. Kornelia Theodosia | 63.0 | 1 | 0 | 13502 | 77.9583 | D7 | S | |
| female | 291 | 1 | Barber, Miss. Ellen "Nellie" | 26.0 | 0 | 0 | 19877 | 78.8500 | NaN | S | |
| female | 292 | 1 | Bishop, Mrs. Dickinson H (Helen Walton) | 19.0 | 1 | 0 | 11967 | 91.0792 | B49 | C | |
| female | 298 | 0 | Allison, Miss. Helen Loraine | 2.0 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | |
| female | 300 | 1 | Baxter, Mrs. James (Helene DeLaudeniere Chaput) | 50.0 | 0 | 1 | PC 17558 | 247.5208 | B58 B60 | C | |
| female | 307 | 1 | Fleming, Miss. Margaret | NaN | 0 | 0 | 17421 | 110.8833 | NaN | C | |
| female | 308 | 1 | Penasco y Castellana, Mrs. Victor de Satode (M... | 17.0 | 1 | 0 | PC 17758 | 108.9000 | C65 | C | |
| female | 310 | 1 | Francatelli, Miss. Laura Mabel | 30.0 | 0 | 0 | PC 17485 | 56.9292 | E36 | C | |
| female | 311 | 1 | Hays, Miss. Margaret Bechstein | 24.0 | 0 | 0 | 11767 | 83.1583 | C54 | C | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3 | male | 825 | 0 | Panula, Master. Urho Abraham | 2.0 | 4 | 1 | 3101295 | 39.6875 | NaN | S |
| male | 826 | 0 | Flynn, Mr. John | NaN | 0 | 0 | 368323 | 6.9500 | NaN | Q | |
| male | 827 | 0 | Lam, Mr. Len | NaN | 0 | 0 | 1601 | 56.4958 | NaN | S | |
| male | 829 | 1 | McCormack, Mr. Thomas Joseph | NaN | 0 | 0 | 367228 | 7.7500 | NaN | Q | |
| male | 833 | 0 | Saad, Mr. Amin | NaN | 0 | 0 | 2671 | 7.2292 | NaN | C | |
| male | 834 | 0 | Augustsson, Mr. Albert | 23.0 | 0 | 0 | 347468 | 7.8542 | NaN | S | |
| male | 835 | 0 | Allum, Mr. Owen George | 18.0 | 0 | 0 | 2223 | 8.3000 | NaN | S | |
| male | 837 | 0 | Pasic, Mr. Jakob | 21.0 | 0 | 0 | 315097 | 8.6625 | NaN | S | |
| male | 838 | 0 | Sirota, Mr. Maurice | NaN | 0 | 0 | 392092 | 8.0500 | NaN | S | |
| male | 839 | 1 | Chip, Mr. Chang | 32.0 | 0 | 0 | 1601 | 56.4958 | NaN | S | |
| male | 841 | 0 | Alhomaki, Mr. Ilmari Rudolf | 20.0 | 0 | 0 | SOTON/O2 3101287 | 7.9250 | NaN | S | |
| male | 844 | 0 | Lemberopolous, Mr. Peter L | 34.5 | 0 | 0 | 2683 | 6.4375 | NaN | C | |
| male | 845 | 0 | Culumovic, Mr. Jeso | 17.0 | 0 | 0 | 315090 | 8.6625 | NaN | S | |
| male | 846 | 0 | Abbing, Mr. Anthony | 42.0 | 0 | 0 | C.A. 5547 | 7.5500 | NaN | S | |
| male | 847 | 0 | Sage, Mr. Douglas Bullen | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S | |
| male | 848 | 0 | Markoff, Mr. Marin | 35.0 | 0 | 0 | 349213 | 7.8958 | NaN | C | |
| male | 851 | 0 | Andersson, Master. Sigvard Harald Elias | 4.0 | 4 | 2 | 347082 | 31.2750 | NaN | S | |
| male | 852 | 0 | Svensson, Mr. Johan | 74.0 | 0 | 0 | 347060 | 7.7750 | NaN | S | |
| male | 860 | 0 | Razi, Mr. Raihed | NaN | 0 | 0 | 2629 | 7.2292 | NaN | C | |
| male | 861 | 0 | Hansen, Mr. Claus Peter | 41.0 | 2 | 0 | 350026 | 14.1083 | NaN | S | |
| male | 869 | 0 | van Melkebeke, Mr. Philemon | NaN | 0 | 0 | 345777 | 9.5000 | NaN | S | |
| male | 870 | 1 | Johnson, Master. Harold Theodor | 4.0 | 1 | 1 | 347742 | 11.1333 | NaN | S | |
| male | 871 | 0 | Balkic, Mr. Cerin | 26.0 | 0 | 0 | 349248 | 7.8958 | NaN | S | |
| male | 874 | 0 | Vander Cruyssen, Mr. Victor | 47.0 | 0 | 0 | 345765 | 9.0000 | NaN | S | |
| male | 877 | 0 | Gustafsson, Mr. Alfred Ossian | 20.0 | 0 | 0 | 7534 | 9.8458 | NaN | S | |
| male | 878 | 0 | Petroff, Mr. Nedelio | 19.0 | 0 | 0 | 349212 | 7.8958 | NaN | S | |
| male | 879 | 0 | Laleff, Mr. Kristo | NaN | 0 | 0 | 349217 | 7.8958 | NaN | S | |
| male | 882 | 0 | Markun, Mr. Johann | 33.0 | 0 | 0 | 349257 | 7.8958 | NaN | S | |
| male | 885 | 0 | Sutehall, Mr. Henry Jr | 25.0 | 0 | 0 | SOTON/OQ 392076 | 7.0500 | NaN | S | |
| male | 891 | 0 | Dooley, Mr. Patrick | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 10 columns
by_grp1 = titanic_idx.groupby(level=['pclass','sex'])
by_grp1
<pandas.core.groupby.DataFrameGroupBy object at 0x10f0b4828>
# Define the function to compute spread
def spread(series):
return series.max() - series.min()
# Aggregate by using the dictionary
aggregator = {'survived':'sum', 'age':'mean', 'fare':spread}
aggr = by_grp1.agg(aggregator)
aggr
| fare | survived | age | ||
|---|---|---|---|---|
| pclass | sex | |||
| 1 | female | 486.4000 | 91 | 34.611765 |
| male | 512.3292 | 45 | 41.281386 | |
| 2 | female | 54.5000 | 70 | 28.722973 |
| male | 73.5000 | 17 | 30.740707 | |
| 3 | female | 62.8000 | 72 | 21.750000 |
| male | 69.5500 | 47 | 26.507589 |
Grouping on a function of the index
# make test data
dates = pd.date_range('20161001', periods=30)
df = pd.DataFrame(np.random.rand(30,3).round(2), index=dates, columns=list('ABC'))
df.index.name = 'Date'
df.head()
| A | B | C | |
|---|---|---|---|
| Date | |||
| 2016-10-01 | 0.03 | 0.31 | 0.05 |
| 2016-10-02 | 1.00 | 0.04 | 0.10 |
| 2016-10-03 | 0.06 | 0.66 | 0.36 |
| 2016-10-04 | 0.60 | 0.37 | 0.27 |
| 2016-10-05 | 0.78 | 0.21 | 0.59 |
by_day = df.groupby(df.index.strftime('%a'))
by_day['C'].sum()
Fri 1.64
Mon 2.23
Sat 1.32
Sun 2.46
Thu 1.42
Tue 2.41
Wed 2.51
Name: C, dtype: float64
Detecting outliers with Z-Scores
from scipy.stats import zscore
import warnings
warnings.simplefilter(action = "ignore", category = RuntimeWarning)
cars = pd.read_csv('data/automobile.csv')
cars.head()
| symboling | normalized_losses | maker | fuel | aspiration | doors | body | wheels | engine_location | wheel_base | ... | engine_size | fuel_system | bore | stroke | compression_ratio | horsepower | peak_rpm | city_mpg | highway_mpg | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 164 | audi | gas | std | four | sedan | fwd | front | 99.8 | ... | 109 | mpfi | 3.19 | 3.4 | 10.0 | 102 | 5500 | 24 | 30 | 13950 |
| 1 | 2 | 164 | audi | gas | std | four | sedan | 4wd | front | 99.4 | ... | 136 | mpfi | 3.19 | 3.4 | 8.0 | 115 | 5500 | 18 | 22 | 17450 |
| 2 | 1 | 158 | audi | gas | std | four | sedan | fwd | front | 105.8 | ... | 136 | mpfi | 3.19 | 3.4 | 8.5 | 110 | 5500 | 19 | 25 | 17710 |
| 3 | 1 | 158 | audi | gas | turbo | four | sedan | fwd | front | 105.8 | ... | 131 | mpfi | 3.13 | 3.4 | 8.3 | 140 | 5500 | 17 | 20 | 23875 |
| 4 | 2 | 192 | bmw | gas | std | two | sedan | rwd | front | 101.2 | ... | 108 | mpfi | 3.50 | 2.8 | 8.8 | 101 | 5800 | 23 | 29 | 16430 |
5 rows × 26 columns
np.seterr(divide='ignore')
standardized = cars.groupby('cylinders')['city_mpg','price'].transform(zscore)
# identify outliers
outliers = (standardized['city_mpg'] < -3) | (standardized['city_mpg'] > 3)
cars.loc[outliers]
| symboling | normalized_losses | maker | fuel | aspiration | doors | body | wheels | engine_location | wheel_base | ... | engine_size | fuel_system | bore | stroke | compression_ratio | horsepower | peak_rpm | city_mpg | highway_mpg | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 19 | 2 | 137 | honda | gas | std | two | hatchback | fwd | front | 86.6 | ... | 92 | 1bbl | 2.91 | 3.41 | 9.6 | 58 | 4800 | 49 | 54 | 6479 |
| 60 | 1 | 128 | nissan | diesel | std | two | sedan | fwd | front | 94.5 | ... | 103 | idi | 2.99 | 3.47 | 21.9 | 55 | 4800 | 45 | 50 | 7099 |
2 rows × 26 columns
Filling missing data (imputation) by group
titanic.tail()
| id | survived | pclass | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.00 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.00 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.45 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | Q |
# Write a function that imputes median
def impute_median(series):
return series.fillna(series.median())
# grouping by sex & pclass
by_sex_class = titanic.groupby(['sex','pclass'])
# sex & pclass 그룹별로 median 값을 missing data에 할당
titanic['age'] = by_sex_class['age'].transform(impute_median)
titanic.tail()
| id | survived | pclass | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.00 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.00 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | 21.5 | 1 | 2 | W./C. 6607 | 23.45 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | Q |
transformations with .apply
def disparity(gr):
# spread
s = gr['fare'].max() - gr['fare'].min()
# z-score
z = (gr['fare'] - gr['fare'].mean())/gr['fare'].std()
return pd.DataFrame({'zscore':z , 'spread':s})
by_class = titanic.groupby('pclass')
by_class['fare'].mean()
pclass
1 84.154687
2 20.662183
3 13.675550
Name: fare, dtype: float64
pgroup_disp = by_class.apply(disparity) # 모든 row에 대해 각각 적용됨.
pgroup_disp.head()
| spread | zscore | |
|---|---|---|
| 0 | 69.5500 | -0.545549 |
| 1 | 512.3292 | -0.164217 |
| 2 | 69.5500 | -0.488239 |
| 3 | 512.3292 | -0.396205 |
| 4 | 69.5500 | -0.477626 |
# C deck 의 생존율
def c_deck_survival(gr):
c_passengers = gr['cabin'].str.startswith('C').fillna(False)
return gr.loc[c_passengers, 'survived'].mean()
titanic.groupby('sex').apply(c_deck_survival)
sex
female 0.888889
male 0.343750
dtype: float64
# 10살 기준 생존율
under10 = (titanic['age'] < 10).map({True:'under 10', False:'over 10'}) # Create the Boolean Series
survived_mean_1 = titanic.groupby(under10)['survived'].mean()
survived_mean_1
age
over 10 0.366707
under 10 0.612903
Name: survived, dtype: float64
survived_mean_2 = titanic.groupby([under10, 'pclass'])['survived'].mean()
survived_mean_2
age pclass
over 10 1 0.629108
2 0.419162
3 0.222717
under 10 1 0.666667
2 1.000000
3 0.452381
Name: survived, dtype: float64
4. Excercise
medals = pd.read_csv('data/olympic_medals.csv')
medals.head()
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Athens | 1896 | Aquatics | Swimming | HAJOS, Alfred | HUN | Men | 100m freestyle | M | Gold |
| 1 | Athens | 1896 | Aquatics | Swimming | HERSCHMANN, Otto | AUT | Men | 100m freestyle | M | Silver |
| 2 | Athens | 1896 | Aquatics | Swimming | DRIVAS, Dimitrios | GRE | Men | 100m freestyle for sailors | M | Bronze |
| 3 | Athens | 1896 | Aquatics | Swimming | MALOKINIS, Ioannis | GRE | Men | 100m freestyle for sailors | M | Gold |
| 4 | Athens | 1896 | Aquatics | Swimming | CHASAPIS, Spiridon | GRE | Men | 100m freestyle for sailors | M | Silver |
# 국가별 메달 합계
medals['NOC'].value_counts()[0:10]
USA 4335
URS 2049
GBR 1594
FRA 1314
ITA 1228
GER 1211
AUS 1075
HUN 1053
SWE 1021
GDR 825
Name: NOC, dtype: int64
# count medals by type
counted = medals.pivot_table(index='NOC', values='Athlete', columns='Medal', aggfunc='count')
counted['totals'] = counted.sum(axis='columns') # Create the new column
counted = counted.sort_values('totals', ascending=False)
counted.head()
| Medal | Bronze | Gold | Silver | totals |
|---|---|---|---|---|
| NOC | ||||
| USA | 1052.0 | 2088.0 | 1195.0 | 4335.0 |
| URS | 584.0 | 838.0 | 627.0 | 2049.0 |
| GBR | 505.0 | 498.0 | 591.0 | 1594.0 |
| FRA | 475.0 | 378.0 | 461.0 | 1314.0 |
| ITA | 374.0 | 460.0 | 394.0 | 1228.0 |
# drop_duplicates
ev_gen = medals[['Event_gender', 'Gender']]
ev_gen_uniques = ev_gen.drop_duplicates()
ev_gen_uniques
| Event_gender | Gender | |
|---|---|---|
| 0 | M | Men |
| 348 | X | Men |
| 416 | W | Women |
| 639 | X | Women |
| 23675 | W | Men |
medals_by_gender = medals.groupby(['Event_gender', 'Gender'])
medal_count_by_gender = medals_by_gender.count()
medal_count_by_gender
| City | Edition | Sport | Discipline | Athlete | NOC | Event | Medal | ||
|---|---|---|---|---|---|---|---|---|---|
| Event_gender | Gender | ||||||||
| M | Men | 20067 | 20067 | 20067 | 20067 | 20067 | 20067 | 20067 | 20067 |
| W | Men | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Women | 7277 | 7277 | 7277 | 7277 | 7277 | 7277 | 7277 | 7277 | |
| X | Men | 1653 | 1653 | 1653 | 1653 | 1653 | 1653 | 1653 | 1653 |
| Women | 218 | 218 | 218 | 218 | 218 | 218 | 218 | 218 |
medals[(medals.Event_gender == 'W') & (medals.Gender == 'Men')]
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|
| 23675 | Sydney | 2000 | Athletics | Athletics | CHEPCHUMBA, Joyce | KEN | Men | marathon | W | Bronze |
# distinct : nunique()
# 국가별로 메달을 획득한 종목 수
country_grouped = medals.groupby('NOC')
Nsports = country_grouped['Sport'].nunique()
Nsports = Nsports.sort_values(ascending=False)
Nsports.head()
NOC
USA 34
GBR 31
FRA 28
GER 26
CHN 24
Name: Sport, dtype: int64
# USA vs. USSR
during_cold_war = (medals.Edition>=1952) & (medals.Edition<=1988)
is_usa_urs = medals.NOC.isin(['USA', 'URS'])
cold_war_medals = medals.loc[during_cold_war & is_usa_urs]
country_grouped = cold_war_medals.groupby('NOC')
Nsports = country_grouped['Sport'].nunique().sort_values(ascending=False)
Nsports
NOC
URS 21
USA 20
Name: Sport, dtype: int64
medals_won_by_country = medals.pivot_table(index='Edition', columns='NOC', values='Athlete', aggfunc='count')
cold_war_usa_usr_medals = medals_won_by_country.loc[1952:1988, ['USA','URS']] # Slice
most_medals = cold_war_usa_usr_medals.idxmax(axis='columns')
most_medals.value_counts()
URS 8
USA 2
dtype: int64
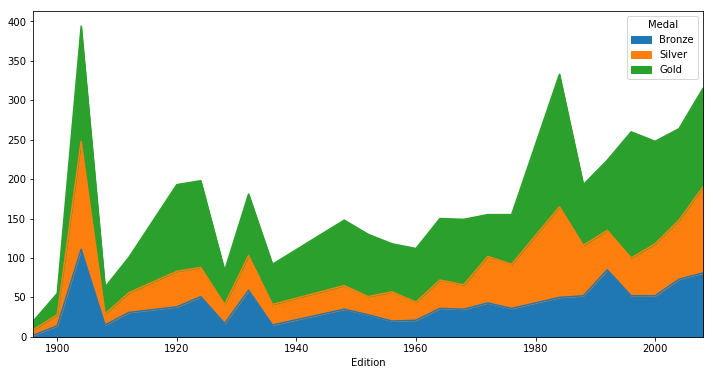
# USA Medal Counts by Edition
usa = medals[medals.NOC == 'USA']
usa_medals_by_year = usa.groupby(['Edition', 'Medal'])['Athlete'].count()
# Reshape
usa_medals_by_year = usa_medals_by_year.unstack(level='Medal')
# Line Plot
usa_medals_by_year.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x10efad0b8>
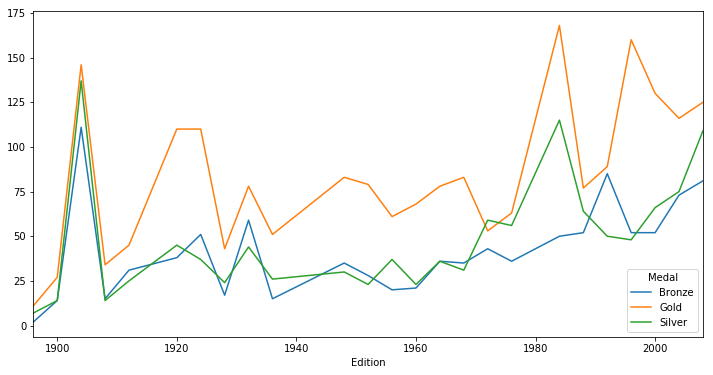
# Area Plot
usa_medals_by_year.plot.area()
<matplotlib.axes._subplots.AxesSubplot at 0x112b3d2b0>
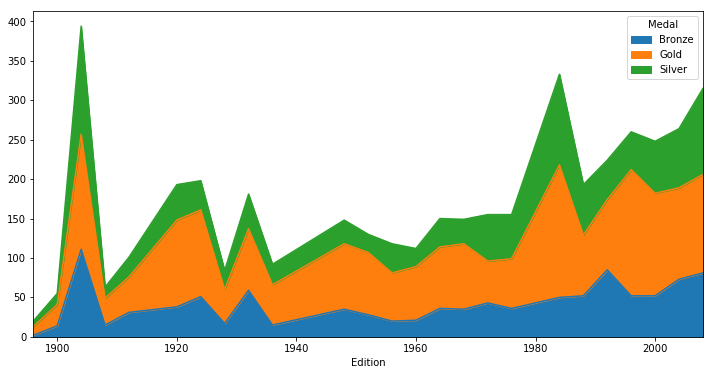
# Area Plot with Ordered Medals
# Redefine 'Medal' as an ordered categorical
medals.Medal = pd.Categorical(values=medals.Medal, categories=['Bronze', 'Silver', 'Gold'], ordered=True)
# Create the DataFrame
usa = medals[medals.NOC == 'USA']
usa_medals_by_year = usa.groupby(['Edition', 'Medal'])['Athlete'].count()
usa_medals_by_year = usa_medals_by_year.unstack(level='Medal')
usa_medals_by_year.plot.area()
<matplotlib.axes._subplots.AxesSubplot at 0x112b56630>